有些东西在任何时间任何地方表示的意思是不变的,比如整数,你看到的就是它表示的东西。关键词也一样,你不能使用 def,class 这些关键词作为变量名,所以当你看到它们的时候,你可以很容易知道它们是做什么的。不过还有很多东西的意思取决于它们所处的情境,也就是它们在不同的时间不同的地方的意思可能是会有变化的。
self 表示的是当前或者默认的对象,在程序运行的时候每次它都会表示一个特定的对象。永远都只会有一个 self ,但是它表示的东西是会变的。
作用域(scope)的规则决定了变量的可见性。你要知道所在的地方受哪个作用域的影响,这样你才能明白哪些变量表示的是什么,不致于把它们跟在其它的作用域的同名变量混淆。
知道当前是在哪个作用域,了解 self 表示的对象是谁,这样你才能明白到底发生了什么,才可以快速的分析遇到的问题。
下午 5:54 ***
self
下午6:07 ***
使用关键词 self 可以得到当前对象。在程序运行中,有且只有一个 self 。成为 self 有一些特权,一会儿我们会看到。永远都只会有一个当前对象或者叫 self 。是谁在哪里会成为 self 是有一些规则的。
在顶级的 self 对象
这里说的顶级的意思是,在任何的类或模块定义之外的地方。比如,打开一个空白的文件,输入:
x = 1这样我们就创建了一个在顶级的本地变量 x ,下面的代码就是在顶级创建了一个方法:
def mend看一下在顶级的 self 是谁,执行一下:
puts self返回的是:
mainmain 是一个特别的词,它表示的就是 self 本身,比如我们可以这样试一下:
m = self在类,模块定义里的 self
在类与模块定义里,self 指的就是类或模块对象。
下面这个实验会告诉你 self 在类的定义与模块的定义里面表示的是谁,做个实验:
class C puts '类:' # self 是 C puts self
module M puts '模块:' # self 是 C::M puts self end puts '回到类级别:' # self 又是 C puts selfend进入类或模块的定义区域以后,类与模块对象就变成了 self。上面的例子,最开始 self 表示的是 C 类这个对象。进入定义模块的区域的时候,self 是 C::M ,表示 C 类里面嵌套的模块 M。回到定义 C 类以后,self 表示地又会是这个类对象,也就是 C。
在定义实例方法里的 self
在实例方法的定义里的 self 很微秒,因为 Ruby 的解释器遇到 def/end 以后,它会立即定义方法。这时候方法定义里的代码还没被执行呢。你看到的屏幕上定义的方法,你只知道当方法被调用的时候,self 会是调用方法的那个对象。在定义方法的那个时候,最多你只能说的是,在这个方法里面的 self 会是未来的那个调用方法的对象。
做个实验:
class C def x puts "Class C, method x:" puts self endend
c = C.newc.xputs "That was a call to x by: #{c}"会输出:
Class C, method x:#
独立方法与类方法中的 self
执行一个独立方法的时候,self 表示的就是拥有这个方法的那个对象。
下面这个实验,先创建了一个对象,又在这个对象里定义了一个独立方法,然后调用这个独立方法,看一下 self 表示的是谁。实验:
obj = Object.newdef obj.show_me puts "Inside singleton method show_me of #{self}"end
obj.show_meputs "Back from call to show_me by #{obj}"会输出:
Inside singleton method show_me of #
class C def C.x puts "Class method of class C" puts "self: #{self}" endendC.x会输出:
Class method of class Cself: C在类的内部我们可以使用 self 表示类的名字:
class C def self.x puts "Class method of class C" puts "self: #{self}" endend如果我们:
class D < CendD.x输出的会是:
Class method of class Cself: Dself 作为默认的信息接收者
2016年9月8日
调用方法就是发送信息给对象,像这样:
obj.talkticket.venue'abc'.capitalize在调用方法的时候如果信息的接收者是 self,可以忽略掉接收者还有点,Ruby 会使用 self 作为默认的接收者,意思就是你发送的信息会发送给 self 。像这样:
talkvenuecapitalize如果有个变量叫 talk,还有个方法叫 talk,调用 talk 的时候只是用了一个 talk,那么变量的优先级会更高一些。遇到这种情况你可以在调用 talk 方法的时候加上 self,像这样: self.talk,或者加上括号:talk() 。
class C def C.no_dot puts '只要 self 是 C,你就可以不用点来调用这个方法' end no_dotend
C.no_dot第一回调用 no_dot 的时候没有明显的接收者,Ruby 看到它以后,会判断你的意思可能是:
self.no_dot在上面这个例子里,self.no_dot 跟 C.no_dot 是不一样的东西,因为我们在定义 C 的区块里,这样 self 就是 C。结果就是方法被调用了,然后我们就看到了输出了结果。
第二次我们使用 C.no_dot 的时候,已经是在定义类的区块以外了,所以 C 就不再是 self 了。也就是想要调用 no_dot ,我们就得指定这个信自的接收者,也就是 C。
上面这个例子输出的结果就是两次调用 no_dot 方法的结果:
只要 self 是 C,你就可以不用点来调用这个方法只要 self 是 C,你就可以不用点来调用这个方法最常见的使用这种无点调用方法,就是当你在另一个实例方法里去调用一个实例方法,再看个例子:
class C def x puts '这是方法 x' end
def y puts '这是方法 y,我要无点调用 x' x endend
c = C.newc.y输出的结果是:
这是方法 y,我要无点调用 x这是方法 x上面调用 c.y 的时候,执行了方法 y ,self 指的是 c(c 是 C 的一个实例)。在 y 里面,使用了 x,它被解释成信息要发送给 self ,这样也就会执行了方法 x 。
有一种情况你不能忽略掉对象加点的形式去调用方法,就是如果方法的名字里面带等号(设置器方法),也就是如果你想调用在 self 上的 venue= 这个方法,你需要这样做:self.venue = 'Town Hall',而不是这样:venue = 'Town Hall'。因为 Ruby 会一直认为 identifier = value 是在分配值给一个本地变量。
无点方法调用,在一个方法里使用另一个的方法的时候很有用,再来看一个例子:
class Person attr_accessor :first_name, :middle_name, :last_name
def whole_name n = first_name + ' ' n << "#{middle_name} " if middle_name n << last_name endend
david = Person.new
david.first_name = 'David'david.last_name = 'Black'
puts "David 的全名是:#{david.whole_name}"
david.middle_name = 'Alan'puts "David 的全名现在是:#{david.whole_name}"输出的结果会是:
David 的全名是:David BlackDavid 的全名现在是:David Alan Black通过 self 解释实例变量
在 Ruby 程序里,任何的实例变量都会属于当前对象。
先做个实验,看看下面的东西会输出什么:
class C def show_var @v = 'I am an instance variable initialized to a string.' puts @v end @v = "instance variables can appear anywhere..."end
C.new.show_var会输出:
I am an instance variable initialized to a string.在上面的代码里,有两个 @v,一个是在方法定义内,另一个是在方法定义外,它们之间没有任何联系。它们同样都是实例变量,并且名字都是 @v,不过它们不是同一个变量,它们会属于不同的对象。
第一次出现的 @v 是在方法定义区块里,也就是 C 类里面的一个实例方法,这样 C 类的每一个实例对象里面都会有它们自己的实例变量 @v 。
第二次出现的 @v 属于 C 这个类对象。类本身也是对象。
every instance variable belongs to whatever object is playing the role of self at the moment the code containing the instance variable is executed.重新再写一下上面的例子:
class C puts "* 类定义区块" puts " | --- self 是:#{self}" @v = '我是 @v' puts " | --- #{@v} 实例变量,属于:#{self} \n\n"
def show_var puts "* 实例方法定义区块" puts " | --- self 是:#{self}" puts " | --- @v 实例变量属于:#{self}" print " | --- @v 的值是:" p @v endend
c = C.newc.show_var执行代码输出的结果是:
* 类定义区块| --- self 是:C| --- 我是 @v 实例变量,属于:C
* 实例方法定义区块| --- self 是:#
上午11:15 ***
作用域指的就是标识符的可见性,特别指的是变量与常量。不同类型的标识符有不同的作用域规则。在两个方法里使用同一个名字的变量 x ,跟在两个地方使用全局变量 $x,会有不同的结果。因为本地与全局变量的作用域不一样。
全局作用域与全局变量
全局作用域覆盖了整个程序。全局变量用的是全局作用域,在任何地方你都可以使用它们。即使你开启了新的类或方法的定义,或者 self 的身份变了,初始的全局变量仍然可用。
下面这个例子,在定义类的主体里可以使用初始化的全局变量:
$gvar = "我是全局变量"class C def examine_global puts $gvar endend
c = C.newc.examine_global输出的结果会是:
我是全局变量本地作用域
class,module,def 都会创建新的本地作用域。
做个实验:
class C a = 1
def local_a a = 2 puts a end
puts aend
c = C.newc.local_a输出的结果是:
12第一次出现的本地变量 a ,是在类定义的本地作用域的下面。第二次出现的 a,是在方法定义的本地作用域的下面。结束了方法定义以后,本地作用域回到了类区块,这里要求输出的 a 就是在类区块这个本地作用域下面声明的本地变量 a ,它的值是 1 。然后我们创建了一个类的实例,调用了它的 local_a 方法,这个方法输出的是在方法定义作用域下面声明的本地变量 a 的值,也就是 2 。
在嵌套类与模块的时候,每次遇到新的定义区块以后就会创建一个新的本地作用域。
再试一下:
class C a = 5
module M a = 4
module N a = 3
class D a = 2
def show_a a = 1 puts a end puts a end puts a end puts a end puts aend
d = C::M::N::D.newd.show_a输出的结果会是:
23451任何的 class,module 或 method 都会开启一个新的本地作用域,每个作用域都可以有属于自己的全新的本地变量。
本地作用域与 self
先看个例子:
class C def x(value_for_a, recurse=false) a = value_for_a print "现在 self 是: " p self puts "现在 a 是:" puts a if recurse puts "\n调用自己..." x("a 的第二个值") puts "调用自己结束以后,a 是:" puts a end endend
c = C.newc.x("a 的第一个值", true)运行的结果会是:
现在 self 是: #
调用自己...现在 self 是: #
然后到了做决定的时候了(if recurse),调用自己不调用自己,这会由 recurse 变量决定。如果调用自己,就会调用方法 x ,调用的时候没有指定 recurse 参数的值,这个参数默认的值是 false,所以调用它自己的时候就不会再继续的调用它自己了。
调用自己的时候给 value_for_a 参数设置了一个不同的值(“a 的第二个值”),也就是会在调用的时候输出不同的信息。不过调用自己回来以后,我们发现这次运行的 x 里的 a 的值没有改变(还是 “a 的第一个值”)。也就是每一次我们调用 x 的时候,都会生成一个新的本地作用域,即使 self 并没有改变。
常量的作用域
下午1:06 ***
在类与方法定义区块里可以定义常量。如果你知道定义时使用的嵌套,你就可以在任何地方访问到常量。来看个例子:
module M class C class D module N X = 1 end end endend比如我要访问在模块 N 里定义的常量 X,这样做:
M::C::D::N::X得到常量的位置也可以是相对的,下面的例子验证了这个说法:
module M class C class D module N X = 1 end end puts D::N::X endend在 C 类里,得到模块 N 里的 X,用的是 D::N::X 。
有时候你不想使用相对的路径得到常量。比如我们想创建的类跟 Ruby 内置的类名字一样,比如 Ruby 里面有个 String(字符串) 类,如果你创建了一个 Violin(小提琴),里面也可能会有一个 String (弦)。像这样:
class Violin class String attr_accessor :pitch def initialize(pitch) @pitch = pitch end end
def initialize @e = String.new("E") @a = String.new("A") ...etc...上面使用 String 的时候指的是我们自己定义的 String 类,如果你想使用 Ruby 内置的 String 类,可以使用常量分隔符(::,两个冒号),像这样:
::String.new('hello')类变量,作用域,可见性
下午1:50 ***
类变量是维护类状态用的,它们的名字用两个 @ 符号开头,比如 @@var。类变量并不是类作用域,它们是类层次作用域。类变量提供了在类与类的实例对象之间共享数据的机制,也就是类变量在类方法定义与实例方法定义上都是可见的,有时候在顶级的类定义上也是。除此以外,类变量在其它的对象上是不可见的。
来看个例子,先用类方法 Car.add_make(make) 注册洗车生产商,然后用 Car.new(make) 造几辆汽车:
Car.add_make("Honda")Car.add_make("Ford")
h = Car.new("Honda")f = Car.new("Ford")h2 = Car.new("Honda")程序会告诉你创建的汽车:
创建新的 Honda!创建新的 Ford!创建新的 Honda!下午2:08 **
下午2:27 **
同一个汽车生产商生产了多少个 h2?我们会使用实例方法 make_mates 查到:
puts "统计 h2 汽车的数量..."puts "一共有 #{h2.make_mates} 辆"一共有多少辆汽车?这需要用到类,而不是每个单独的汽车,所以我们可以问一下类:
puts "统计汽车的总数..."puts "一共有 #{Car.total_count} 辆"输出的应该是:
统计汽车的总数...一共有 3 辆"试一下创建一辆没有汽车生产商的汽车:
x = Car.new("Brand X")会报错:
car.rb:21:in `initialize': No such make: Brand X. (RuntimeError)代码如下:
class Car @@makes = [] @@cars = {} @@total_count = 0 attr_reader :make def self.total_count @@total_count end
def self.add_make(make) unless @@makes.include?(make) @@makes << make @@cars[make] = 0 end end
def initialize(make) if @@makes.include?(make) puts "创建新的汽车生产商:#{make}" @make = make @@cars[make] += 1 @@total_count += 1 else raise "没有汽车生产商:#{make}" end end
def make_mates @@cars[self.make] endend在类的顶部定义了三个类变量。@@makes 是一个数组,存储汽车生产商的名字。@@cars 是 hash,里面是名值对类型的数据。@@cars 里的数据的名字是汽车生产商汽车的汽车,对应的数据是汽车的数量。@@total_count 里面存储的是一共生产了多少辆汽车。
Car 类里还有个 make 可读属性,创建了汽车以后必须设置 make 属性的值。这里没有关于汽车生产商的可写的属性,因为我们不希望类的代码之后可以改变已有的汽车生产商。
要访问到 @@total_count 类变量,Car 类里还定义了一个 total_count 方法,它会返回类变量当前的值。还有一个类方法是 add_make,这个方法接收一个参数,会把参数的值放到表示汽车生产商的数组里,用的是 << 操作符。在这个方法里我们先要确定添加的汽车生产商还不存在,如果不存在就把它放到表示汽车生产商的类变量里 @@makes,同时也会设置一下 @@cars ,让这个汽车生产商生产的汽车等于零。意思就是还没有这个汽车生产商生产的汽车。
然后到了 initialize 方法了,在这里创建新的汽车。每辆新车都需要一个汽车生产商,如果汽车生产商不存在,也就是它不在 @@makes 数组里,就触发一个错误。如果汽车生产商存在,我们会为汽车的 make 属性设置合适的值,让这个汽车生产商生产的汽车的数量增加一(@@cars),同时也让生产的汽车总数增加一(@@total_count)。
还有一个 make_mates 方法,可以返回某个汽车生产商生产的所有的汽车。
注意上面在 initialize 方法里,还有在类方法里,比如 Car.total_count,Car.add_make 上面,都使用了类变量。类内部的实例方法 initialize,与类方法是在不同的作用域下。但它们属于同一个类,所以可以使用类变量在它们之间共享数据。
类变量与类层次
之前我们已经说过了,类变量使用的不是类作用域,也是类层次的作用域。看个例子:
class Parent @@value = 100end
class Child < Parent @@value = 200end
class Parent puts @@valueend输出的结果会是 200。Child 是 Parent 的一个子类,也就是 Parent 与 Child 共享同样的类变量。在 Child 里面设置 @@value 的时候,你设置的是唯一的在 Parent 与 Child 上的 @@value 。
下午3:17 ***
方法访问规则
下午3:18 ***
现在我们已经知道了 Ruby 程序会发送信息给对象,对象主要干的事儿就是对这些信息做出回应。有时候,对象希望可以给自己发送信息,但是不希望别人给它们发送信息。这种情况,我们可以让方法变成私有的。
访问有几个访问级别,私有(private),保护(protected),公开(public)。public 是默认的访问级别,发送给对象的信息大部分调用的就是有公开访问级别的方法。
私有方法
把对象想成是一个你要求让他做任务的人,比如你想让某个人给你烤个蛋糕,为了给你烤这个蛋糕,烤蛋糕的人会做一系列的任务,比如打个鸡蛋,和个面什么的。烤蛋糕的人会做这些事儿,不过他可能并不想对所有这些事情做出回应。你要求的只是“请给个烤个蛋糕”。剩下的事儿交给蛋糕师就可以了。
用代码模拟一下,创建个文件名字是 baker.rb,代码如下:
class Cake def initialize(batter) @batter = batter @baked = true endend
class Eggend
class Flourend
class Baker def bake_cake @batter = [] pour_flour add_egg stir_batter return Cake.new(@batter) end
def add_egg @batter.push(Egg.new) end
def stir_batter end
private :pour_flour, :add_egg, :stir_batterend上面用了一个 private 方法,你可以把想变成私有方法的名字告诉它。如果不加参数,它就像是一个开关,它下面定义的所有的实例方法都会是私有方法,直到调用 public 或 protected 。
你不能:
b = Baker.newb.add_egg这样调用 add_egg 会报错:
`
如果我们不加信息的接收者:
add_egg是否能单独调用这个方法?信息会发送到哪里?如果没有对象处理信息,那方法怎么被调用?调用方法的时候如果不指定信息的接收者,Ruby 会把信息发送给当前对象,也就是 self 表示的那个对象。
你可以推断出来,能对 add_egg 这个信息作出回应的对象,只能是 self 表示的那个可以对 add_egg 作出回应的对象。也就是我们只能在当 self 是 Baker 的实例的时候才能调用 add_egg 这个实例方法。
私有方法与独立方法
私有方法与独立方法不是一回事。独立方法只属于一个对象。私有方法可以属于多个对象,不过只有在正确的情况下才能被调用。决定可以调用私有方法的不是你发送信息到的对象,而是你发送信息的时候 self 表示的那个对象。
保护方法
保护方法是一种温柔点私有方法。规则像这样:
you can call a protected method on an object x, as long as the default object (self) is an instance of the same class as x or of an ancestor or descendant class of x’s class.保护方法主要的目的就是,你可以在某个类的一个实例上使用这个类的另一个实例去做点事儿。来看个例子:
class C def initialize(n) @n = n end
def n @n end
def compare(c) if c.n > n puts "另一个对象的 n 更大一些" else puts "另一个对象的 n 一样或更小一些" end end protected :nend
这就需要使用一个保护方法。让 n 成为保护方法,而不是私有方法,c1 可以让 c2 去执行方法 n,因为 c1 跟 c2 是同一个类的实例对象。但是如果你试着在 C 对象上面调用 n 方法,会失败,因为 C 并不是 C 类的一个实例。
子类也会继承使用超级类上的方法访问规则,不过你可以在子类里覆盖掉这些规则。
下午4:35 ***
顶级方法
下午4:35 ***
用 Ruby 做的最自然的事情就是去设计类,模块,还有实例化类。不过有时候你想快速的写一些脚本,不想把代码放到一个类里面,你可以在顶级(top-level)去定义与使用这些方法。做这样的事儿就是在顶级默认的对象里面写代码,这个对象叫 main,它是自动生成的 Object 的一个实例,这么做主要是因为必须得有一个东西是 self,即使是在顶级。
定义顶级方法
在顶级定义个方法:
def talk puts 'hello'end在顶级上定义的方法会作为 Object 类的一个实例上的私有的方法。上面的代码就相当于是:
class Object private
def talk puts 'hello' endend调用这些方法的时候必须使用裸字风格,也就是不能指定信息的接收者,因为它们是私有方法。Object 的私有实例方法可以在任何地方调用,因为 Object 是在所属的方法查找路径里面,所以顶级的方法会一直有效。
再看个例子:
def talk puts 'hello'end
puts "不加接收者执行 talk"talkputs "加个接收者执行 talk"obj = Object.newobj.talk第一次执行 talk 能成功,第二次执行的时候会报错,因为调用私有方法的时候不能指定接收者。
预定义的顶级方法
puts,print 都是 Kernel 的内置的私有实例方法,查看所有在 Kernel 上提供的私有方法:
ruby -e 'p Kernel.private_instance_methods.sort'
-
 王者荣耀火力官网正版下载安装 v3.74.1.61900MB角色扮演
王者荣耀火力官网正版下载安装 v3.74.1.61900MB角色扮演 -
 蜡笔小新之小帮手大作战免费版39.96MB休闲益智
蜡笔小新之小帮手大作战免费版39.96MB休闲益智 -
 啸风蛮荒专属角色扮演
啸风蛮荒专属角色扮演 -
 宠物美国鹰生活模拟3D 435M模拟经营
宠物美国鹰生活模拟3D 435M模拟经营 -
 巴尔干驾驶区229.45MB赛车游戏
巴尔干驾驶区229.45MB赛车游戏 -
 香肠派对ss2正式服下载安装 v13.701910MB角色扮演
香肠派对ss2正式服下载安装 v13.701910MB角色扮演






- 推荐阅读阅读排行
-
-
 RobinsWereld官网在哪下载最新官方下载安装地址03-10发布
RobinsWereld官网在哪下载最新官方下载安装地址03-10发布 -
 原神谜境悬兵第一关宝箱在哪里在哪03-10发布
原神谜境悬兵第一关宝箱在哪里在哪03-10发布 -
 梦幻西游灵心护神树攻略03-10发布
梦幻西游灵心护神树攻略03-10发布 -
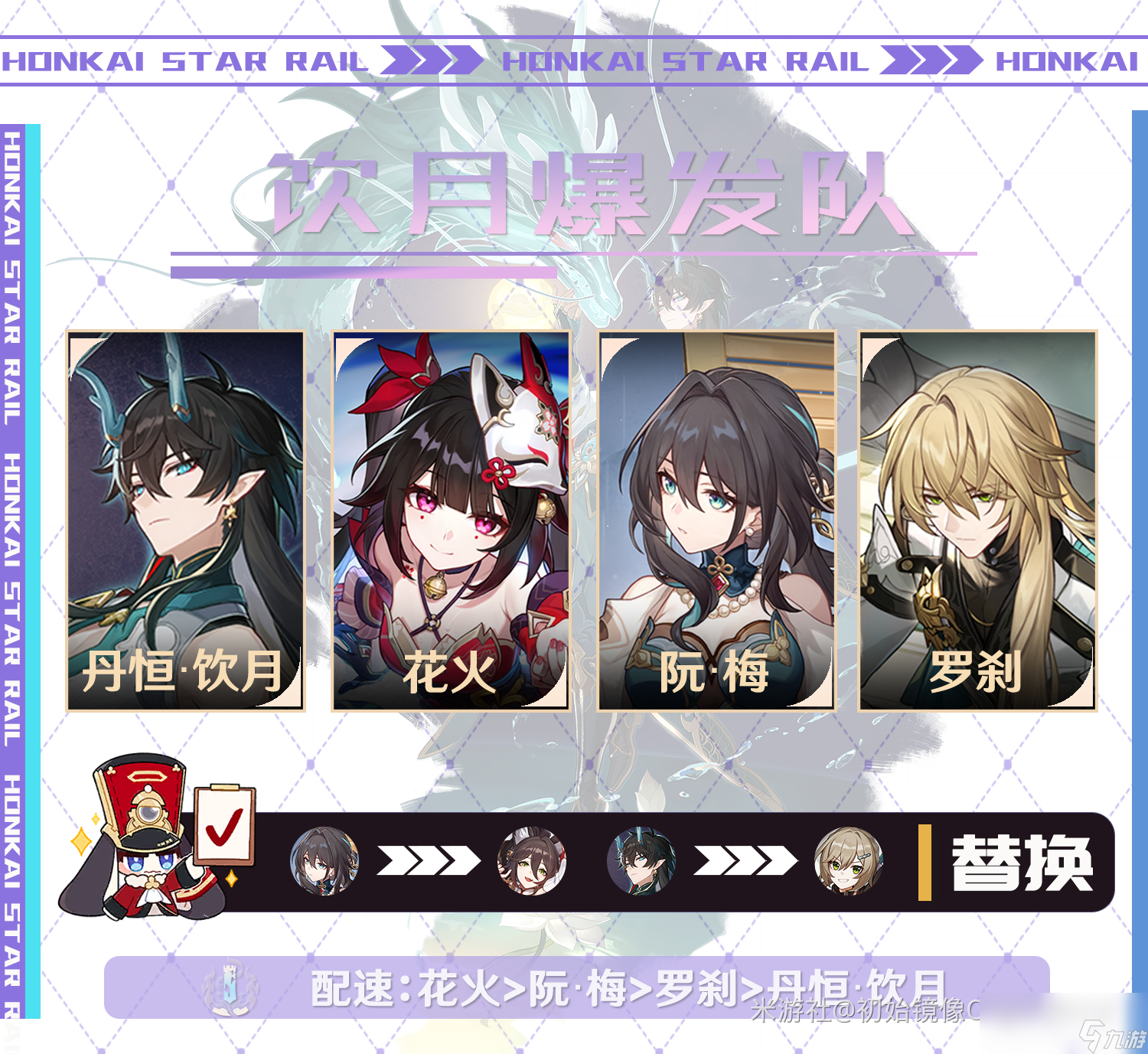 崩坏星穹铁道2024花火阵容搭配03-10发布
崩坏星穹铁道2024花火阵容搭配03-10发布 -
 崩坏星穹铁道希儿词条选择搭配攻略03-10发布
崩坏星穹铁道希儿词条选择搭配攻略03-10发布
-




- 手游开服新游开测
-
-










- 推荐下载下载排行
-
-




